 GoodDrag: Towards Good Practices for Drag Editing with Diffusion Models
GoodDrag: Towards Good Practices for Drag Editing with Diffusion Models
- Zewei Zhang1
- Huan Liu1
- Jun Chen 1
- Xiangyu Xu 2✉
Abstract
In this paper, we introduce GoodDrag, a novel approach to improve the stability and image quality of drag editing. Unlike existing methods that struggle with accumulated perturbations and often result in distortions, GoodDrag introduces an AlDD framework that alternates between drag and denoising operations within the diffusion process, effectively improving the fidelity of the result. We also propose an information-preserving motion supervision operation that maintains the original features of the starting point for precise manipulation and artifact reduction. In addition, we contribute to the benchmarking of drag editing by introducing a new dataset, Drag100, and developing dedicated quality assessment metrics, Dragging Accuracy Index and Gemini Score, utilizing Large Multimodal Models. Extensive experiments demonstrate that the proposed GoodDrag compares favorably against the state-of-the-art approaches both qualitatively and quantitatively. The source code and data will be released.
Method
Existing diffusion-based drag editing methods (dotted trajectory), typically perform all drag operations at once, followed by denoising steps to correct the resulting perturbations. However, this approach often leads to accumulated perturbations that are too substantial for high-fidelity correction. In contrast, the proposed AlDD framework (solid trajectory) alternates between drag and denoising operations within the diffusion process, effectively preventing the accumulation of large perturbations and ensuring more accurate editing results. The drag operation modifies the image to achieve the desired dragging effect but introduces perturbations that deviate the intermediate result from the natural image manifold. The denoising operation, on the other hand, is trained to estimate the score function of the natural image distribution, guiding intermediate results back to the image manifold.
Overview of the proposed AlDD framework. (a) Existing methods first perform all drag editing operations \( \{g_k\}_{k=1}^K \) at a single time step \( T \) and subsequently apply all denoising operations \( \{f_t\}_{t=T}^1 \) to transform the edited image \( z_T^K \) into the VAE image space. (b) To mitigate the accumulated perturbations in (a), AlDD alternates between the drag operation \( g \) and the diffusion denoising operation \( f \), which leads to higher quality results. Specifically, we apply one denoising operation after every \( B \) drag steps and ensure the total number of drag steps \( K \) is divisible by \( B \). We set \( B=2 \) in this figure for clarity.
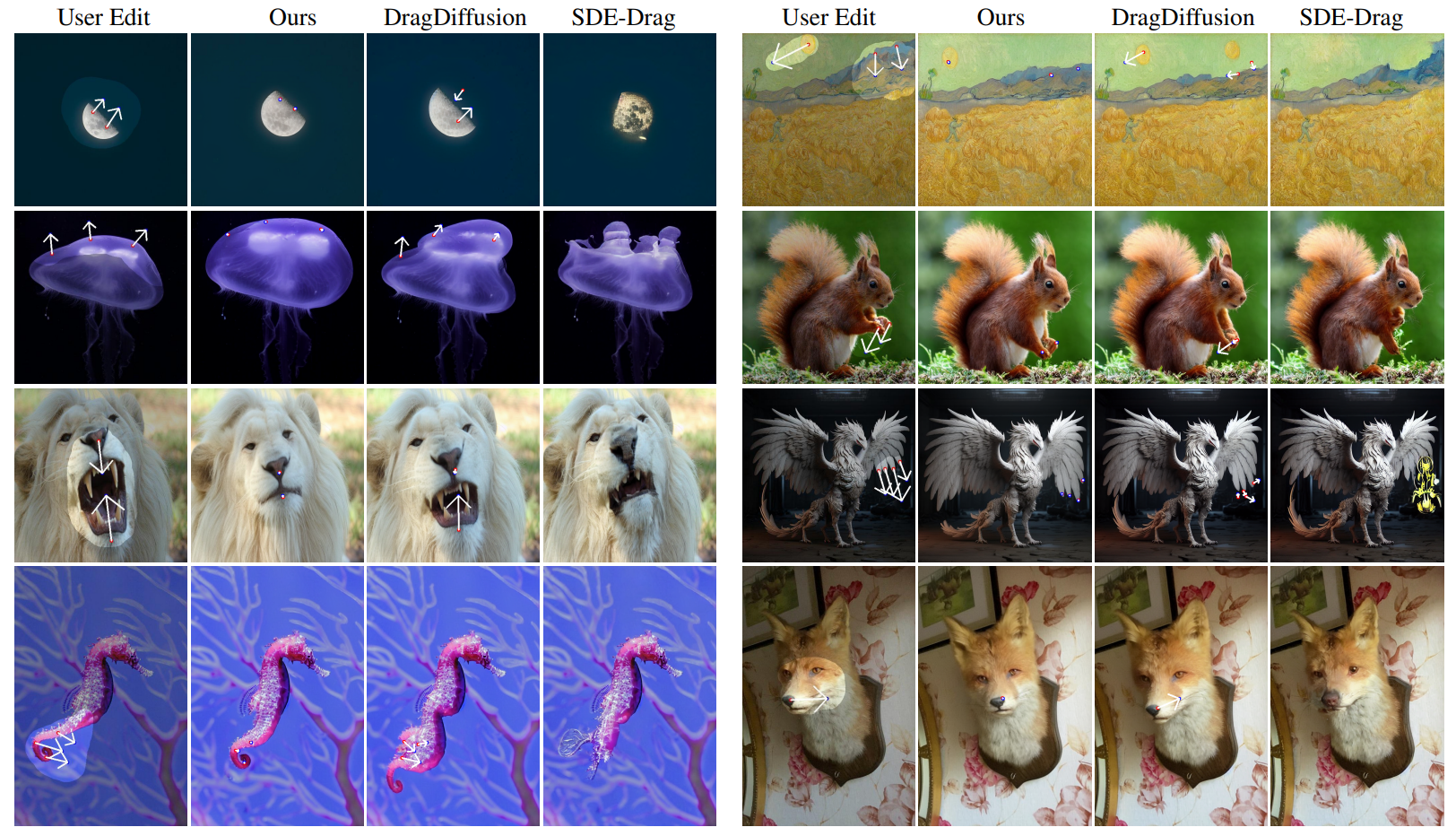
Comparison against SOTA
Visualization of the Dragging Process












Citation
Acknowledgements
The website template was borrowed from Michaël Gharbi, Ref-NeRF and ReconFusion.